



'/%3e%3c/svg%3e) 发布
发布 ;}.c{fill:%233f3f3f;}%3c/style%3e%3cclipPath%20id='a'%3e%3crect%20class='a'%20width='24'%20height='24'%20transform='translate(0%20-0.256)'/%3e%3c/clipPath%3e%3c/defs%3e%3cg%20transform='translate(0%200.256)'%3e%3cg%20class='b'%3e%3cpath%20class='c'%20d='M12.938,13.58a.745.745,0,0,1-.328-.076L4.549,9.523a.741.741,0,0,1,0-1.33L12.61,4.212a.74.74,0,0,1,.657,0l8.061,3.981a.741.741,0,0,1,0,1.33L13.267,13.5a.741.741,0,0,1-.329.076M6.553,8.858l6.385,3.153,6.386-3.153L12.938,5.705Z'%20transform='translate(-1.067%20-1.067)'/%3e%3cpath%20class='c'%20d='M12.939,20.964a.729.729,0,0,1-.328-.077l-8.062-3.98a.742.742,0,1,1,.657-1.33l7.733,3.818,7.733-3.818a.742.742,0,1,1,.657,1.33l-8.062,3.98a.729.729,0,0,1-.328.077'%20transform='translate(-1.067%20-3.999)'/%3e%3cpath%20class='c'%20d='M12.939,26.964a.729.729,0,0,1-.328-.077l-8.062-3.98a.742.742,0,1,1,.657-1.33l7.733,3.818,7.733-3.818a.742.742,0,1,1,.657,1.33l-8.062,3.98a.729.729,0,0,1-.328.077'%20transform='translate(-1.067%20-5.547)'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
;}.c{fill:%233f3f3f;}%3c/style%3e%3cclipPath%20id='a'%3e%3crect%20class='a'%20width='24'%20height='24'%20transform='translate(0%200.225)'/%3e%3c/clipPath%3e%3c/defs%3e%3cg%20transform='translate(0%20-0.225)'%3e%3cg%20class='b'%3e%3cpath%20class='c'%20d='M21.648,9.056a.754.754,0,0,0-.215-.535l-5.3-5.3a.752.752,0,0,0-.535-.215V3H7.375A2.377,2.377,0,0,0,5,5.376V20.307a2.377,2.377,0,0,0,2.375,2.376h11.9a2.378,2.378,0,0,0,2.376-2.376V9.056ZM16.355,5.584,19.07,8.3H16.923a.569.569,0,0,1-.568-.568Zm2.924,15.584H7.375a.862.862,0,0,1-.861-.861V5.376a.862.862,0,0,1,.861-.861h7.466V7.731a2.084,2.084,0,0,0,2.082,2.082H20.14V20.307a.863.863,0,0,1-.861.861'%20transform='translate(-1.215%20-0.729)'/%3e%3cpath%20class='c'%20d='M10.757,15.514H15.3A.757.757,0,0,0,15.3,14H10.757a.757.757,0,0,0,0,1.514'%20transform='translate(-2.43%20-3.402)'/%3e%3cpath%20class='c'%20d='M18.327,20h-7.57a.757.757,0,0,0,0,1.514h7.57a.757.757,0,0,0,0-1.514'%20transform='translate(-2.43%20-4.86)'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)

;}.cls-3{fill:%23dbdbdb;}.cls-4{stroke:%23333;stroke-miterlimit:10;stroke-width:0.5px;}%3c/style%3e%3cclipPath%20id='clip-path'%3e%3crect%20class='cls-1'%20width='22'%20height='22'/%3e%3c/clipPath%3e%3c/defs%3e%3cg%20class='cls-2'%3e%3cpath%20class='cls-3'%20d='M16.89,7.8s-1,4.28-4,6a21,21,0,0,1-6.55,1.66,9.87,9.87,0,0,0,6.38,1c3.47-.72,6.82-4.66,6.71-5.43A5.88,5.88,0,0,0,17.6,8.17,2.76,2.76,0,0,0,16.89,7.8Z'/%3e%3cellipse%20class='cls-4'%20cx='11'%20cy='10.94'%20rx='8.53'%20ry='5.49'/%3e%3ccircle%20class='cls-4'%20cx='11'%20cy='10.94'%20r='2.49'/%3e%3c/g%3e%3c/svg%3e)
一、 项目背景与简介
本项目基于飞凌 RK1126B(RV1126) 工业级嵌入式平台,针对工业产线拉线缺陷开发了一套高效、低延迟的端侧(Edge AI)智能视觉检测系统。通过软硬件协同优化,实现单帧视觉智能识别与结果实时追溯分流。
二、 核心技术栈
硬件平台:飞凌 OK1126B(瑞芯微 RV1126),利用片上内置 NPU 提供矩阵级硬件加速。
操作系统:嵌入式 Linux Buildroot 稳定系统。
开发语言与架构:C++ 多线程架构(采集线程与推理线程异步共享)。
图像及推理框架:OpenCV 4.5.5 (基于 V4L2 摄像头架构) + 瑞芯微官方 RKNN API 运行时驱动。
模型算法:YOLO 系列目标检测模型,支持 FP16 半精度与 INT8 极限定点量化部署。
三、 核心业务逻辑与流程
系统整体运行流程遵循工业自动化高内聚标准,主要包含以下核心节点:
1. 硬件联动触发 (GPIO 信号检测)
系统在主循环中实时挂起死等 Linux 内核中物理 GPIO 23 的引脚状态。只有当光耦或外部接近传感器传来高电平信号(值为1)时,系统才会被唤醒并向下执行,极大降低了闲时芯片的功耗与发热量。
2. ROI 局部精准区域裁剪
为彻底剔除工业现场复杂的背景环境干扰,并压缩 NPU 算力开销,系统利用 OpenCV 的 cv::Rect 算子对摄像头捕获的原始图像进行特定的 ROI(感兴趣区域) 局部动态裁剪(当前裁剪视窗为 400x300),并将其无损缩放、转换颜色空间至 640x640 RGB 输入格式送入 NPU。
3. NPU 亚毫秒级高速推理
通过高效调用底层 rknn_run 及 rknn_outputs_get API,NPU 在端侧进行直接矩阵计算。在工程实践中,模型在 FP16 格式下的单帧纯推理耗时成功压榨并稳定在 35毫秒以内,满足产线高速运转的实时性要求。
4. 工业级质量追溯与数据分流 (PASS/FAIL 闭环)
系统会对每一次触发行为进行无条件的“全捕捉、全打标、全留存”处理(调试阶段全保存):
PASS (合格品):NPU 成功捕捉到目标拉线,且模型返回的实时置信度(Confidence)大于或等于 0.50f。此时系统绘制绿色标志框,在图片叠加水印状态后,将其写入存储目录
/userdata/my_model/pass/。FAIL (不合格品/缺陷品):当置信度低于 0.50f,或者画面中未识别到有效目标时,系统一律强制判定为不合格. 此时系统绘制红色警告框,并在图片左上角打标,将其实时存入分离的追溯目录
/userdata/my_model/fail/。
四、 开发日志与环境避坑指南
时钟断电复位:由于板载 RTC 时钟及电池仅维持硬件走时,断电重启后 Linux 系统的 GPIO 节点会丢失映射。重新运行程序前必须通过
echo 23 > /sys/class/gpio/export重新激活引脚。摄像头通道动态漂移:系统自带的虚拟 ISP 通道(如 video31)极易随开机加载时序发生漂移。通过
v4l2-ctl --list-devices抓取总线,最终确认外接 USB 摄像头需强制固定绑定在宿主硬件通道/dev/video52。RKNN是2.3.2版本:RV1126B,官方已经提供RKNN2支持,交叉编译也要选择rv1126b型号。
核心工具链与版本匹配选型避坑(重要)在环境搭建初期,由于参考了网上旧版的 RV1126 博客,导致走了长达数天的弯路。以下为核心版本对齐记录:
❌ 错误尝试 1:Python 选错版本 起初在 Windows 端使用 Anaconda 建立了老旧的 Python 环境,导致 YOLOv5 的新版导出脚本频繁报错,库依赖完全冲突。
❌ 错误尝试 2:模型选错 YOLOv5 官方原生固件 直接使用 YOLOv5 官方最新 master 分支导出的 ONNX 模型,由于里面包含了 NPU 不支持的非常规算子(如
SiLU激活函数、复杂的张量切片等),导致模型转换时直接报错崩溃。❌ 错误尝试 3:Toolkit 工具链选错 1.7.3 版本 根据老版 RV1126 教程下载了
rknn-toolkit 1.7.3(第一代 Toolkit 架构)。在对模型进行 build 转换时,疯狂提示算子不支持或平台不匹配。💡 破局核心指令:开发板 NPU 运行时版本查询 为了查明真实原因,我们在开发板终端中运行了以下指令,直接调取系统内注册的 NPU 驱动版本:
root@OK1126B-buildroot:~# strings /usr/lib/librknnrt.so | grep -i "version" librknnrt version: 2.3.2 (429f9xxx@2025-04-09T09:09:27) 系统返回关键信息:rknn_api version: 2.3.2。这一行返回值直接点醒了我们——飞凌这款最新的官方固件已经在底层将 NPU 驱动全面升级到了 RKNN2 架构(对应版本 2.3.2)!RV1126B 必须使用最新的二代工具链。
✅ 正确环境解决方案(终极对齐):Win主机端:在 Anaconda Navigator 中,重新建立独立的 Python 3.8 虚拟环境(因为 RKNN-Toolkit2 对 Python 3.8 的兼容性最完美)。
模型选择:改用专门针对瑞芯微 NPU 优化过的 rockchip-linux/rknpu2 仓库中推荐的 YOLOv5 结构(将 SiLU 激活函数全部替换为 NPU 硬件支持最好的 ReLU 或 LeakyReLU)。
工具链对齐:全面废弃 1.7.3,在 Ubuntu 虚拟机和 Windows 端统一安装官方最新的 rknn-toolkit2 v2.3.2。至此,.onnx 顺利转为 .rknn,推理通路彻底打通!
五、 开发环境与 YOLOv8 训练部署
1.软硬件基础环境
电脑:Windows 10 IoT + R5600 16G + RTX 5070,安装 KiCad Huaqiu 10.0.2 & VS Code & Anaconda Navigator;
虚拟机:VMware 26H1 安装飞凌官方 Ubuntu,升级到 24 版本;
分工:Windows 主机用来模型标注和训练生成 .onnx`,Ubuntu 用来调试、交叉编译等。
2. Windows端 YOLOv8 虚拟环境搭建与标注坑
为了进行高精度的拉线模型训练,我们在 Windows 宿主机上部署了 YOLOv8 环境。以下为基于 Anaconda Prompt 的具体部署流程与踩坑记录:
环境初始化与建立 在 Anaconda 中创建一个独立的 Python 环境(命名为
yolov8_env):conda create -n yolov8_env python=3.10.20 conda activate yolov8_env安装 YOLOv8 核心依赖
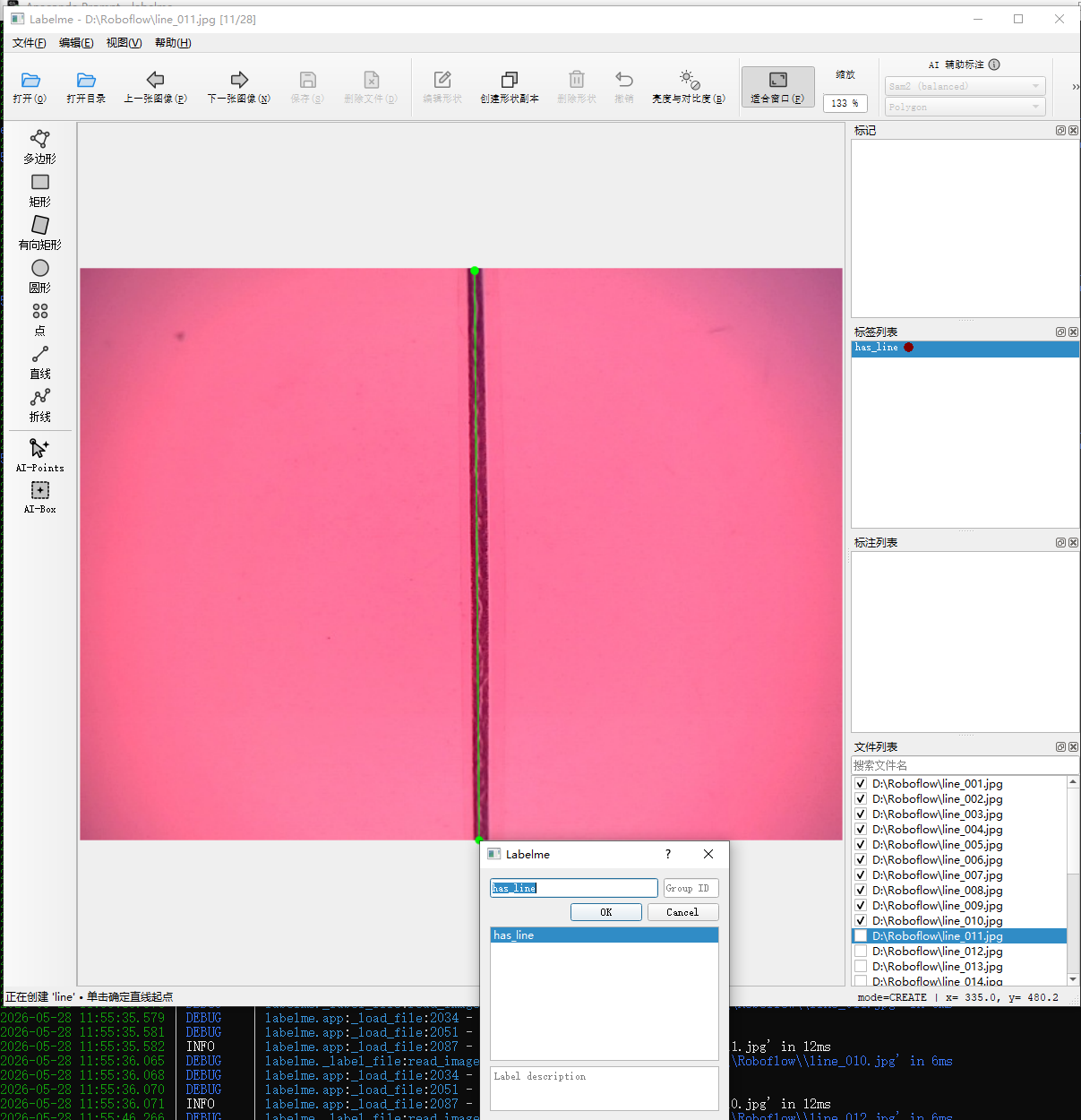
pip install ultralytics标注工具避坑修正 核心结论:针对 Windows 10/11 环境,弃用 LabelImg,改用 Labelme。
插入改用 Labelme的操作方法
问题现象:原先使用的 LabelImg 软件在处理工业现场的高清拉线图片时,极其不稳定。启动后在执行 Open Dir 或进行矩形框选操作时,会出现无预警直接闪退(软件原地消失),且无任何报错日志。
原因分析:经排查,该类软件基于较旧的 Python 图形库,在 Windows 某些 UI 渲染层级与新一代系统底层存在严重的显存渲染冲突(特别是高分辨率图片载入时)。
最终解决方案:
彻底放弃 LabelImg:停止尝试修复该软件的兼容性。
切换至 Labelme:采用 Labelme 进行多边形标注。
成功标志:改用 Labelme 后,标注流程完全稳定,未再出现一次闪退,已顺利完成 50 张样本图片的整编与格式统一(line_xxx.jpg)。
环境配置(Labelme 运行指南):
#推荐创建独立环境
conda create -n label_env python=3.9
conda activate label_env
pip install labelme
#若遇偶尔缓存崩溃,执行:
rm ~/.labelmerc标注 检查 yolo_dataset 目录结构: 转换完成后,你的目录下应该自动生成了以下标准的 YOLO 格式:
yolo_dataset/
├── labels/
│ ├── train/ # 存放训练集 .txt 标注文件
│ └── val/ # 存放验证集 .txt 标注文件
├── images/
│ ├── train/ # 存放训练集 .jpg 图片文件
│ └── val/ # 存放验证集 .jpg 图片文件请一定要手动检查一下 labels/train 里的一个 .txt 文件,看里面的坐标格式是否是:类别索引 (0) x_center y_center width height。只要是这种格式,你的模型训练就能直接跑通。
用 labelme2yolo 转换很顺利,说明之前标注生成的 JSON 文件格式是标准兼容的。之前 LabelImg 闪退是因为它那个老旧的 UI 渲染器不兼容你现在的系统,而现在这一套命令行工具(labelme + labelme2yolo)才是工业级开发的“稳态”方案。
准备训练 (data.yaml): 现在的目录结构已经齐了,接下来你需要写一个 data.yaml,内容如下(直接复制即可):
path: D:/workspace/wire_detect/yolo_dataset # 改成你的实际路径
train: images/train
val: images/val
nc: 1
names: ['has_line']注意:Labelme输出的格式不是.txt,需要自动转换,如下流程操作:
自动化数据处理 SOP (LabelMe -> YOLO) 这里要感谢Deepseek推荐的这个软件! 本项目采用 labelme2yolo 进行数据处理,具备标注即分流、无需人工二次分配的特性。
1. 自动化转换指令
在终端执行以下指令,即可一键完成所有标注文件的格式转换及 8:2 数据集切分:
# --json_dir: 指向你存放所有 .jpg 和 .json 的文件夹
# --val_size: 设置验证集比例(0.2 即 20% 验证,80% 训练)
labelme2yolo --json_dir D:/workspace/wire_detect/data_raw --val_size 0.22. 工具带来的自动化逻辑
一键分流:该工具会自动将处理后的文件拆分至 labels/train、labels/val、images/train、images/val 四个核心目录。
格式对齐:自动将 LabelMe 的 JSON 坐标(矩形/多边形)精确转换为 YOLOv8 所需的 y_center, x_center, width, height 归一化格式。
防错机制:如果遇到损坏的 JSON 文件,工具会直接跳过并输出错误日志,避免训练中断。
3. 验收标准 (自动化检查清单)
执行转换后,请确认 D:/workspace/wire_detect/yolo_dataset 下包含以下内容:
labels/train:txt 文件数 = 总数 * 0.8。
images/train:图片文件数 = 总数 * 0.8。
labels/val:txt 文件数 = 总数 * 0.2。
images/val:图片文件数 = 总数 * 0.2。 这个是软件操作界面
这个是训练原始图片&生成json,注意记得自动重命名,不要手动:
这个是labelme2yolo 自动转换&重命名生成的目录

自动生成的目录2
推荐另外两个网站,也帮我分析了best.onnx数据结构 https://app.roboflow.com/功能强大,这次来不及学习了
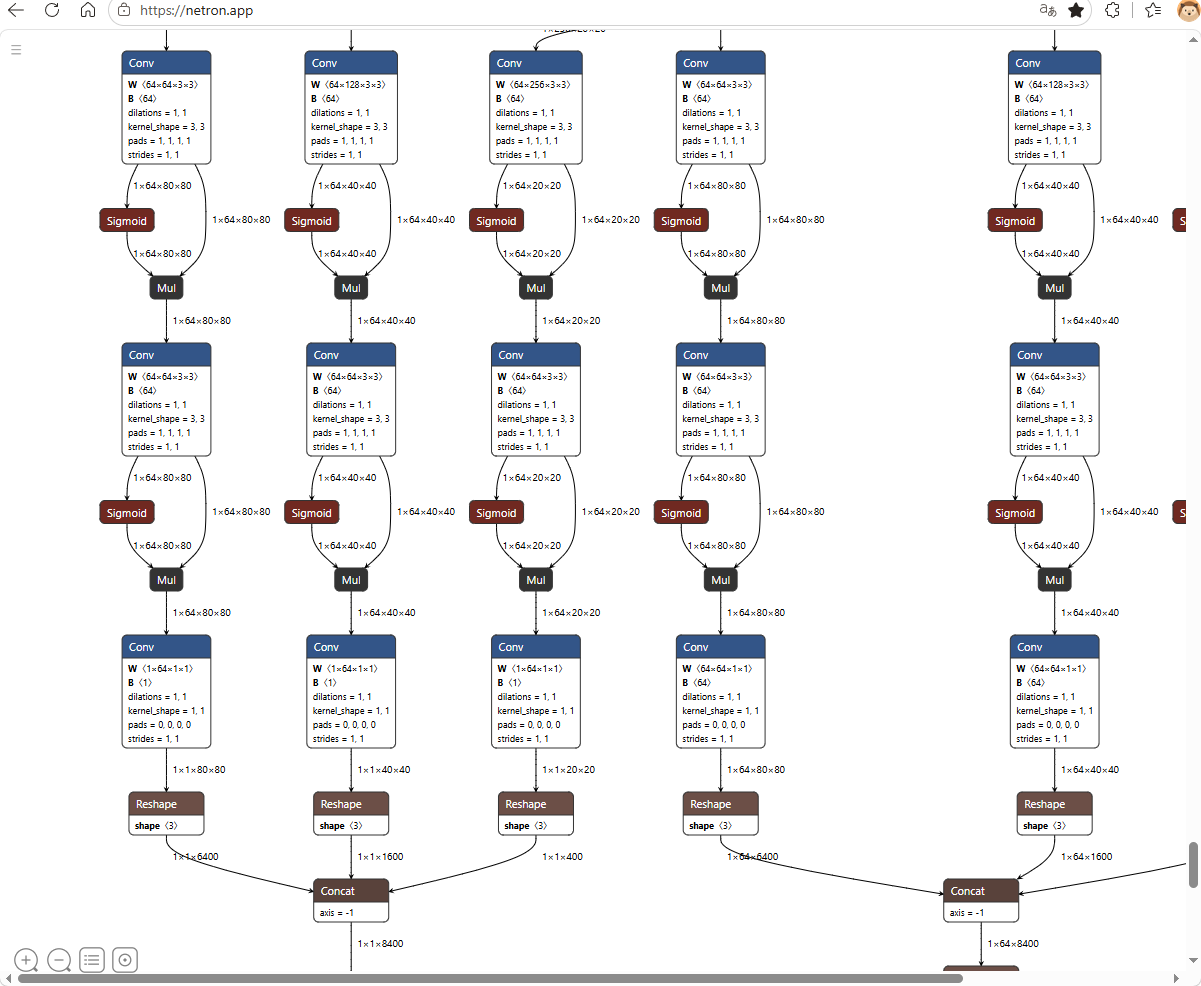
3.RTX 5070 本地化高效模型训练
利用 Windows 主机强悍的硬件:AMD Ryzen 5 5600 处理器 + NVIDIA GeForce RTX 5070 显卡进行本地加速训练:
数据集结构准备:将标注好的数据集转换为 YOLODataset 格式,包含 images 和 labels 文件夹。
启动 100 轮本地训练:
yolo train model=yolov8n.pt data=D:\wire_dataset\images\YOLODataset\data.yaml epochs=100 imgsz=640 device=0
<span class="hljs-bullet">* 训练高光成绩:
<span class="hljs-code">```bash
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 3.8G 0.6425 0.5312 0.9125 14 640
Class Images Instances Box(P R mAP50 mAP50-95)
all 50 5 0.973 1 0.995 0.928
Speed: 0.1ms preprocess, 0.9ms inference, 0.0ms loss, 3.2ms postprocess per image分析:凭借 5070 强大的硬件架构,显存仅占用 3.8G,单帧推理耗时仅 0.9 毫秒。模型收敛极快,最终的 mAP50 指标达到了惊人的 0.995,召回率(R)达到 1,说明对产线拉线的缺陷具备极高的捕捉敏感度!
4. 模型导出 ONNX(转 RKNN 的核心前置步骤)
训练完成后,需要将 PyTorch 的 .pt 权重文件导出为通用的 .onnx 格式。针对端侧 NPU 的限制,在导出时进行了特定的算子约束:
yolo export model=runs/detect/train-3/weights/best.pt format=onnx opset=12⚠️ 避坑划重点:转换时必须显式指定 opset=12!如果使用更高版本的 opset(如 opset=17),ONNX 会包含一些非常新颖的动态分支或动态 shape 算子,而在后续执行 rknn.load_onnx() 转换时,RKNN2 2.3.2 会直接提示无法识别算子,导致全盘卡死。使用 opset=12 导出的 best.onnx 最为稳健,能够完美契合后期的量化与端侧部署。
这个是模型生成目录图片

这个是模型生成目录
六、 开发板和EDA介绍
感谢华秋开源论坛和飞凌嵌入式支持,提供平台和技术支持,软件是华秋最新版的 KiCad Huaqiu 10.0.2
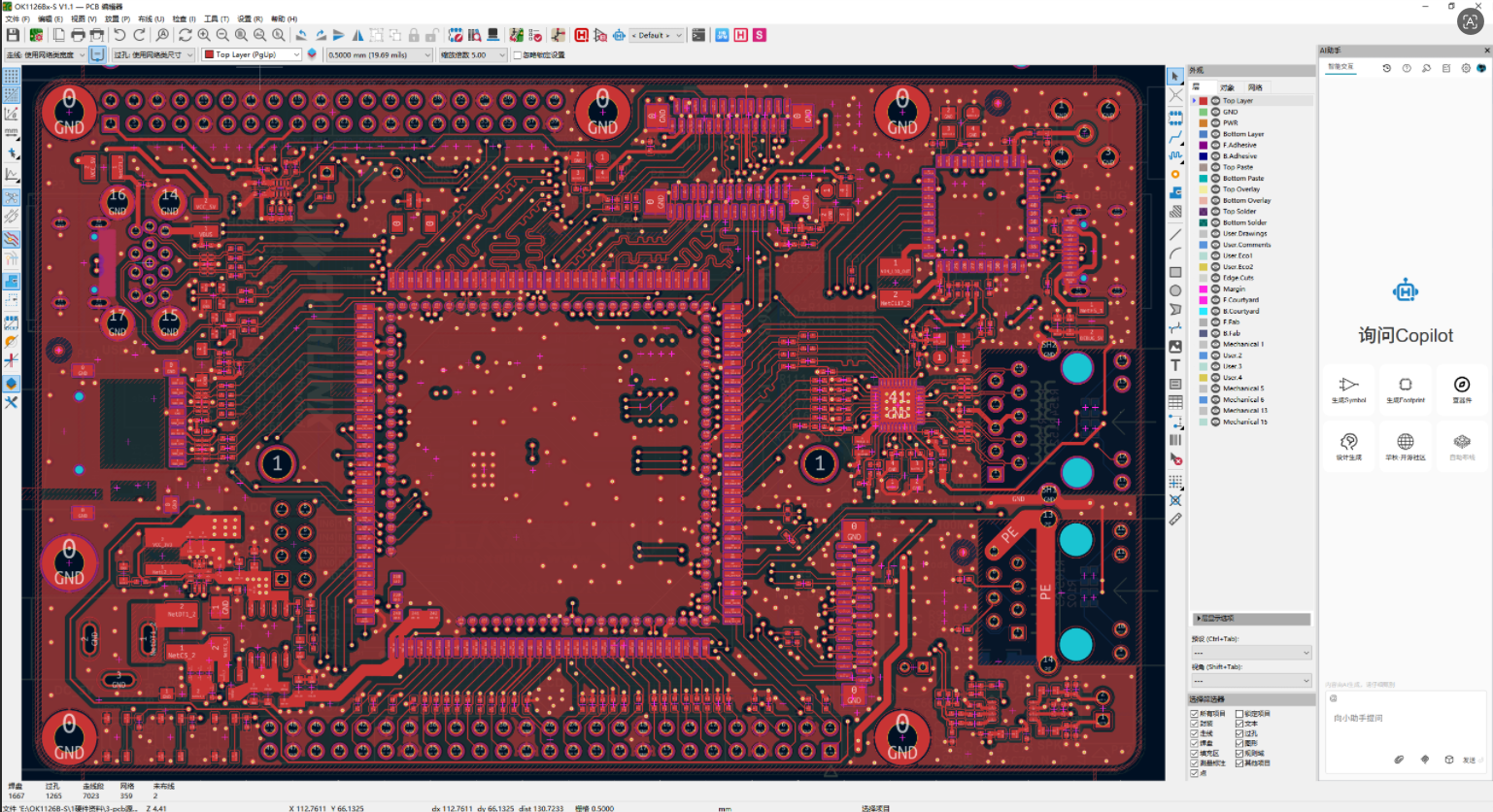
飞凌工程师布线不错,所有IO都加了TVS防护,工业级防护,布局优化合理,走线中规中矩,点赞。
七、 开始测试摄像头取像流程
1. 核心测试指令
开发板通电,查网线,通过IP扫描指令,确定开发板IP为192.168.0.232
ssh 192.168.0.232
#输入默认密码
#或者直接root登录
ssh root@192.168.0.232 在 Linux 系统下,USB 免驱摄像头(标准 UVC 协议)一般会被映射为 /dev/videoX 设备。
2. 查看设备节点
ls /dev/video*描述:插入摄像头前后对比运行该命令,通常会多出 /dev/video0 和 /dev/video1(高版本内核一个用于抓流,一个用于元数据)。
3. 查看摄像头详细参数(分辨率、格式、帧率)
v4l2-ctl --device=/dev/video0 --list-formats-ext描述:这是最核心的命令,用来确认摄像头支持的是 MJPEG 还是 YUYV 格式,以及支持哪些分辨率。(注:若无此命令,需先 apt-get install v4l-utils)。
4. 抓取单张图片(测试采集)
fswebcam -d /dev/video0 -r 1280x720 --no-banner ./test.jpg描述:最简单的静态图片抓取工具。指定设备和分辨率,直接在当前目录生成 test.jpg 验证通路。
4. 实战避坑指南
因为现在的 USB 摄像头很多都是“多接口”复合设备(比如带麦克风、带 H.264/H.265 硬件解码)。
直接用
ls /dev/video会出来一堆节点,让人分不清哪个才是真正能吐出高分辨率、高清(HD)画面的视频流节点。需要的“另外一条指令”是使用 v4l2-ctl 工具来查询设备列举,它会清晰地显示出带 “HD” 或 “Camera” 字样的真实硬件名称和对应的/dev/videoX编号。查看真实摄像头编号(HD设备)有时候系统里会莫名其妙多出好几个
/dev/video节点,使用以下命令可以直接列出设备的物理名称,精准定位真正的硬件。
v4l2-ctl --list-devices描述:运行后系统会按硬件分组显示。你会看到类似下面的输出:
USB 2.0 Camera: HD USB Camera (usb-3f980000.usb-1.2):
/dev/video0
/dev/video1看到带有 “HD” 或 “Camera” 名字下方的第一个节点(通常是序号小的那个,比如 /dev/video0),才是真正支持高清晰度图像采集的真实摄像头编号。 第一张采集图片,记录以下,转换成小的文件了

这个摄像头是以前的工业用的带加热除雾的摄像头,镜头畸变比较大,我后续更换一个镜头测试。画面畸变会小很多。
八.开始测试GPIO流程
1. 测试 GPIO 23(输入:接传感器/光耦)
测试目的:验证外面传感器亮灯时,开发板能不能收到 3.3V 的高电平信号。
#1. 导出引脚(激活 GPIO 23)
echo 23 > /sys/class/gpio/export
#2. 设置为输入模式
echo in > /sys/class/gpio/gpio23/direction
#3. 查看当前电平状态(反复敲这行命令测试)
cat /sys/class/gpio/gpio23/value📊 结果怎么看:
当产线传感器没亮灯时,敲最后一行命令,屏幕应该打印 0(此时万用表量引脚是 0V)。 当用手挡住传感器或者拉线模型到位、传感器亮灯时,敲最后一行命令,屏幕应该打印 1(此时万用表量引脚是 3.3V)。 如果传感器亮灯了,系统读出来还是 0,说明外面光耦线接错了。
2. 测试 GPIO 25(输出:接报警灯/气缸/PLC)
测试目的:用命令强行让开发板吐出 3.3V 电压,看看外面的报警灯能不能亮,以此证明板子的输出控制是好的。
#1. 导出引脚(激活 GPIO 25)
echo 25 > /sys/class/gpio/export
#2. 设置为输出模式
echo out > /sys/class/gpio/gpio25/direction
#3. 强行输出高电平(让外接的报警灯亮起来)
echo 1 > /sys/class/gpio/gpio25/value
#4. 强行输出低电平(让外接的报警灯熄灭)
echo 0 > /sys/class/gpio/gpio25/value📊 结果怎么看: 当你输入 echo 1 后,外面的报警灯应该瞬间亮起(此时用万用表量 25 号引脚和 GND,应该是稳稳的 3.3V)。 当你输入 echo 0 后,报警灯应该立马熄灭(此时万用表量出来是 0V)。
💡 顺哥贴心提醒:
如果提示 -bash: echo: write error: Device or resource busy,说明这两个引脚已经被你之前运行的旧程序(或者开机自启脚本)占用了。不用慌,直接执行下面这两行命令释放它们,重新配置即可:
echo 23 > /sys/class/gpio/unexport
echo 25 > /sys/class/gpio/unexport九.嵌入式 NPU 部署环境配置与 ONNX 转换指南
1. Ubuntu 系统 Python 3.8 环境搭建
飞凌嵌入式 Linux 系统通常预装了基础 Python,但为了确保交叉编译环境与 RKNN-Toolkit2 兼容,建议使用虚拟环境管理。
#1. 更新源并安装 Python3.8 及开发库
sudo apt update
sudo apt install python3.8 python3.8-dev python3.8-venv -y
#2. 创建专用虚拟环境
python3.8 -m venv rknn_env
source rknn_env/bin/activate
#3. 升级 pip 并安装必要库
pip install --upgrade pip
pip install numpy opencv-python onnx onnxsim2. RKNN 交叉编译工具链 (Toolkit2)
RV1126 平台必须使用 RKNN-Toolkit2 进行模型量化与转换。 版本要求:确保你的 Toolkit2 版本与板子上的驱动版本(2.3.2)一致。 安装方式:
#在虚拟环境中安装 Toolkit2 (请根据你下载的 whl 文件路径安装)
pip install rknn_toolkit2-2.3.2-cp38-cp38-linux_x86_64.whl3. 模型导出与 FP16/INT8 转换命令
由于 RKNN 转换对算子支持有严格限制,必须使用 opset=12 导出。
转换脚本核心逻辑
export_to_rknn.py在Ubuntu 中创建该脚本,将.onnx转换为.rknn:
from rknn.api import RKNN
#初始化
rknn = RKNN(verbose=True)
#1. 配置模型输入:RV1126 平台
rknn.config(target_platform='rv1126', quantization_lib_version='2.3.2')
#2. 加载 ONNX 模型
print("--> Loading model")
rknn.load_onnx(model='best.onnx')
#3. 构建模型 (FP16 为默认,适合快速验证)
#若需 INT8 量化,则需加入 dataset.txt 指向样本数据,并开启 do_quantization=True
print("--> Building model")
rknn.build(do_quantization=False)
#4. 导出 RKNN 文件
rknn.export_rknn('./wire_defect.rknn')
rknn.release()转换命令
python export_to_rknn.py需要把生成的best.rknn通过SCP传送到开发板目录
4. 关键技术参数速查表
项目 | 参数设置 | 备注 |
|---|---|---|
ONNX Opset | 12 | 必须设置为 12,否则 load_onnx() 会崩溃 |
推理精度 | FP16 | 工业检测首选,算子兼容性最好 |
输入尺寸 | 640x640 | 必须与 YOLOv8 训练时 imgsz 一致 |
驱动版本 | 2.3.2 | 开发板驱动必须匹配,否则无法加载 |
5. 避坑指南
为什么选择 FP16 而非 INT8?
INT8 量化需要精细的校准集(Dataset),如果样本中的拉线纹理极其微小,INT8 量化后精度会大幅跳水(mAP 掉点明显)。
RV1126 的 NPU 对 FP16 的支持非常完善,且 35ms 的推理速度对于产线检测已经完全够用,前期建议直接用 FP16。
如果 rknn.build 报错?
算子不支持:检查是否使用了 Flatten 或某些复杂 Slice 算子,建议在导出 ONNX 前使用 onnx-simplifier 进行简化: python -m onnxsim best.onnx best_sim.onnx --input-shape "images,3,640,640"
版本对齐:再次确认:板子终端运行
strings /usr/lib/librknnrt.so | grep -i "version",输出必须是 2.3.2,否则转换出来的 .rknn 放在板子上会报错 version mismatch。
十、交叉编译&开发板运行
开发环境架构说明 (Ubuntu Workspace) 本项目采用模块化工程管理架构,所有核心源代码与编译配置均部署在 Ubuntu 开发机的 ~/workspace/wire_detect/ 目录下。
1. 目录架构树
项目文件结构
~/workspace/wire_detect/
├── src/ # 源码核心库
│ ├── gpio_npu_detect.cpp # 主逻辑:传感器触发、图像流采集与推理调度
│ ├── postprocess.cc # 后处理:NPU 输出数据解析、置信度过滤、框选绘制
│ └── postprocess.h # 接口头文件:定义检测结构体与 API
├── model/ # AI 模型库
│ └── wire_defect.rknn # 部署专用模型文件(由 RKNN-Toolkit2 转换)
├── build/ # 编译构建目录(受版本控制忽略)
├── deploy.sh # 自动化部署脚本(一键编译、同步、运行)
└── README.md # 项目文档2. 编译与部署逻辑 本项目遵循“本地交叉编译 + 远程同步”的开发流:
环境依赖:
Python 3.8+ (用于模型转换)
OpenCV 4.5.5 (用于图像预处理)
RKNN-Toolkit2 (驱动版本:2.3.2)
编译流程: 所有源文件通过 aarch64-none-linux-gnu-g++ 交叉编译器进行编译,确保生成的二进制文件可在飞凌 OK1126B 工业板上运行。
同步机制: 使用 scp 指令将 nnp_detect 和 .rknn 模型自动同步至开发板指定存储区 /userdata/,并通过 ssh 进行远程进程调度与调试。
3. 开发规范
路径守恒:代码中模型加载路径均采用相对路径引用(../model/wire_defect.rknn),禁止在代码中使用绝对路径,以保证工程迁移的灵活性。
数据隔离:所有推理生成的图片结果强制输出至 /userdata/pass/ 或 /userdata/fail/ 目录,防止对根文件系统造成写入压力。
版本控制:建议在 workspace 下定期执行 git 操作,但应通过 .gitignore 将 build/ 和 model/ 等无需版本跟踪的目录排除。
一、交叉编译命令 (在 Ubuntu 下执行)你需要确保这三个文件在同一个目录下,然后执行以下指令进行打包编译:Bash# 假设你在项目根目录下 /opt/gcc-arm-10.3-aarch64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-g++ gpio_npudetect.cpp postprocess.cc -o nnpdetect -I. -I/usr/include/opencv4 -L/usr/lib/aarch64-linux-gnu -lrknnrt -lopencvcore -lopencvimgcodecs -lopencv_imgproc -lpthread
二、 部署与运行 (一键同步)编写一个简单的 run.sh 脚本放在 Ubuntu 项目目录里,以后每次修改代码,只需运行 sh run.sh:Bash#!/bin/bash
1. 编译 g++ gpio_npudetect.cpp postprocess.cc -o nnpdetect -I. -I/usr/include/opencv4 -lrknnrt -lopencvcore -lopencvimgcodecs -lopencv_imgproc -lpthread` 2. 传输 scp nnp_detect wire_defect.rknn root@192.168.0.232:/userdata/` 3. 运行 (通过 SSH 直接执行) ssh root@192.168.0.232 "chmod +x /userdata/nnp_detect && cd /userdata/ && ./nnp_detect"`4. 常见问题排查
报错现象原因分析解决办法
undefined reference to ...postprocess 的头文件没链接好检查 postprocess.h 中是否有 extern "C" 或正确包含
libopencv_... not found交叉编译环境缺少库,确保 Ubuntu 的 /usr/lib/aarch64-linux-gnu 下有这些库
permission denied板子没权限执行,确保在板子上执行了 chmod +xLoad
model failed.rknn 模型路径不对检查代码中 rknn.loadrknn() 的路径是否为 /userdata/wiredefect.rknn
5. 测试验收
流程 (闭环)准备:确认你的三个代码文件和 wiredefect.rknn 模型在同一个文件夹下。
编译:执行上面的 g++ 指令,看到目录下出现了 nnpdetect 可执行文件。
上板:执行
scp nnpdetect wiredefect.rknn root@192.168.0.232:/userdata/调试:在板子上 SSH 执行
./nnp_detect观察控制台输出:如果输出
NPU init success,说明环境通了。如果看到置信度输出,说明模型推理链路通了。
验收:用传感器触发 GPIO,检查 /userdata/pass/ 和 /userdata/fail/ 目录下是否按预期生成了合格/不合格的检测图片。
6. 部分调试结果&照片
交叉编译环境
forlinx@ubuntu:~/SDK $ mkdir -p ~/my_sdk
forlinx@ubuntu:~/SDK $ tar -xzf aarch64-buildroot-linux-gnu_sdk-buildroot.tar.gz -C ~/my_sdk
forlinx@ubuntu:~/SDK $
forlinx@ubuntu:~/my_sdk$ cd ~/my_sdk/aarch64-buildroot-linux-gnu_sdk-buildroot
source ./environment-setup
_ _ _ _ _
| |__ _ _(_) | __| |_ __ ___ ___ | |_
| '_ \| | | | | |/ _` | '__/ _ \ / _ \| __|
| |_) | |_| | | | (_| | | | (_) | (_) | |_
|_.__/ \__,_|_|_|\__,_|_| \___/ \___/ \__|
Making embedded Linux easy!
Some tips:
* PATH now contains the SDK utilities
* Standard autotools variables (CC, LD, CFLAGS) are exported
* Kernel compilation variables (ARCH, CROSS_COMPILE, KERNELDIR) are exported
* To configure do "./configure $CONFIGURE_FLAGS" or use
the "configure" alias
* To build CMake-based projects, use the "cmake" alias
forlinx@ubuntu:~/my_sdk/aarch64-buildroot-linux-gnu_sdk-buildroot$ 以下是编译和运行窗口:
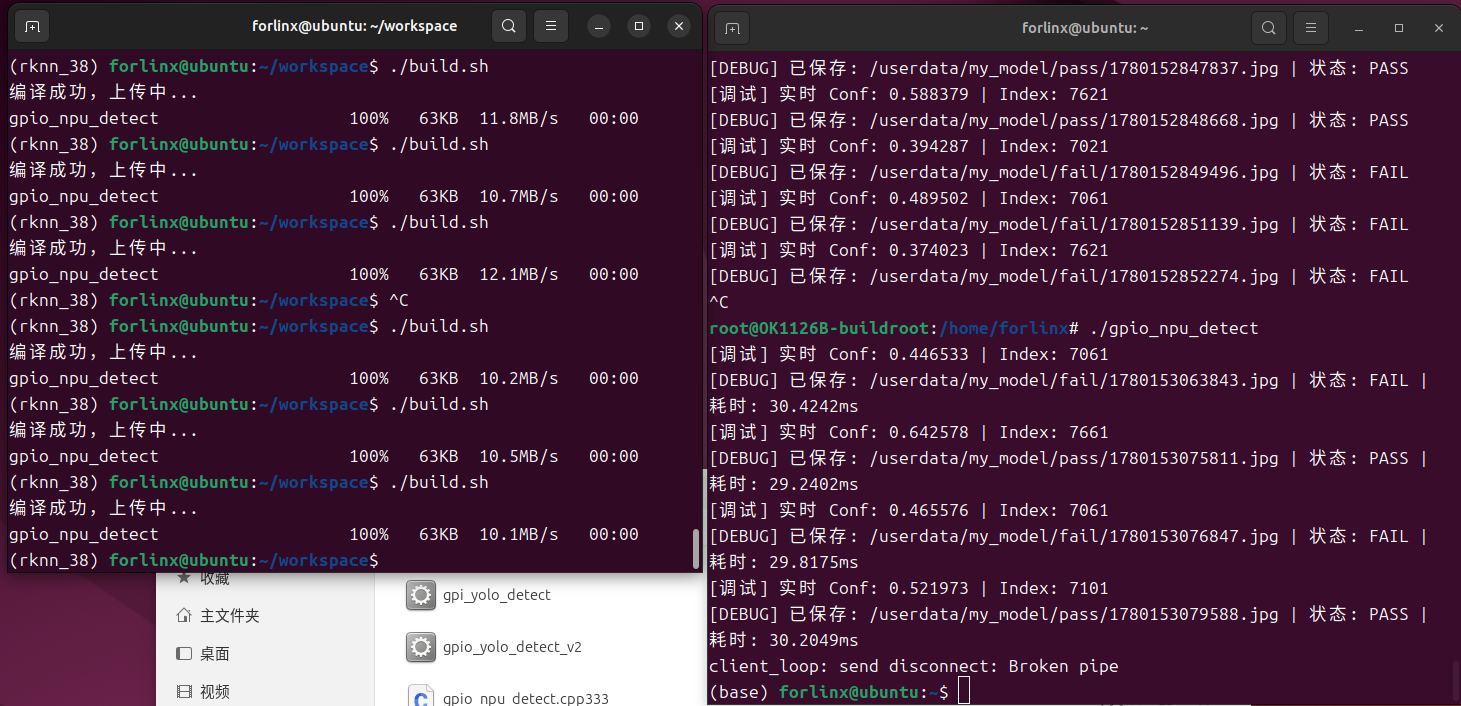
以下是PASS图片

以下是PASS图片

以下是Fail图片,注意参数设置低于0.5F置信度,就判断为失败,微调即可

以下是部分调试过程中的图片

致谢
再一次感谢华秋开源论坛,感谢飞凌工程师指导。感谢网上的公开资料和开源软件等感谢deep seek,Gemini,豆包,谢谢大家无私的分享。如有错误或者侵权,请联系我,请多包涵。
;}.c{fill:%23555;}%3c/style%3e%3cclipPath%20id='a'%3e%3crect%20class='a'%20width='18'%20height='18'%20transform='translate(1543%202144)'/%3e%3c/clipPath%3e%3c/defs%3e%3cg%20class='b'%20transform='translate(-1543%20-2144)'%3e%3cpath%20class='c'%20d='M182.144,108.918a.7.7,0,1,1-1.407,0V98.083l-.033.027-.054.05-5.045,5.045a.7.7,0,0,1-1.041-.945l.046-.05,5.045-5.045a2.508,2.508,0,0,1,3.477-.031l.075.072,4.988,5.022a.7.7,0,0,1-.949,1.038l-.05-.046L182.21,98.2l-.066-.061Zm5.394-15.827a.7.7,0,1,1,0,1.407h-12.2a.7.7,0,1,1,0-1.407Z'%20transform='translate(1370.601%202051.909)'/%3e%3c/g%3e%3c/svg%3e "回到顶部")